Scaling and Developer Productivity at Coinbase - 8 minutes read
 At Coinbase we care about developer productivity. As we’ve scaled from a single service to many, we’ve invested in tools that give us the confidence to rapidly ship new services to production. Like other growing technology companies we’ve been scaling our once monolithic infrastructure through new microservices that encapsulate well defined tasks, buy-down technical debt and help us move fast. As we’ve gone down this path our DevOps team has worked to maintain high developer productivity. We’ve used data to guide our work that we’re now sharing here and hope more people will too. This post takes a glimpse into the data behind deployments at Coinbase and one way we think about developer productivity.
At Coinbase we care about developer productivity. As we’ve scaled from a single service to many, we’ve invested in tools that give us the confidence to rapidly ship new services to production. Like other growing technology companies we’ve been scaling our once monolithic infrastructure through new microservices that encapsulate well defined tasks, buy-down technical debt and help us move fast. As we’ve gone down this path our DevOps team has worked to maintain high developer productivity. We’ve used data to guide our work that we’re now sharing here and hope more people will too. This post takes a glimpse into the data behind deployments at Coinbase and one way we think about developer productivity.In the early days, Coinbase was simple. When we were first able to measure deployment data in early 2015 we ran one production service: coinbase.com. Coinbase is a rails app and we ran on Heroku. Life was good. Deployments were one command, we moved fast and we built a service that laid the foundation for where we are today.
Heroku Makes Deployment Simple. [via]
While running on Heroku in February 2015, we deployed 120 times and our top 3 most frequent deployers on a small team accounted for 58% of all deploys to production. At the time the median deployments per month for an engineer was 8. You can see some of our team’s deployment trends below coming back after winter holidays and ramping up into 2015. Throughout this period, we are only measuring our deployments to Heroku. (Though we launched the service that would become GDAX in February 2015, its early deploys aren’t measured in this dataset).
Early Deployments of Coinbase.com on Heroku, Split by Engineer
With 2015 came two big changes to our infrastructure. Our security and compliance needs grew to accelerate our migration into a more secure environment (we chose AWS) and we started creating new services for the distributed architecture that would power GDAX. To meet both of these goals we designed and started deploying into new cloud infrastructure to securely many services. We started by deploying GDAX and Coinbase soon followed suit.
We need to empower developers to move fast yet provide confidence that systems are safe and secure.
As we designed our new infrastructure and the deployment pipeline that made it accessible, one of the key metrics that we worked to improve was deployment velocity or how often developers were able to safely ship to production. As software continues to eat the world and companies like docker work towards making the internet programmable, developers can be more empowered than ever — unless something is standing in their way. There are several failure scenarios for the company when infrastructures scale and development teams slow down. High quality engineers might leave for a more empowering environment, low bus factors can leave you with poorly understood services or a poorly thought out architecture might make bugs exponentially more difficult to track down. At the pace our industry evolves, slowing the company down wasn’t acceptable. We need to empower developers to move fast yet provide confidence that systems are safe and secure.
One of the key metrics that we worked to improve was deployment velocity or how often developers were able to safely ship to production.
To maintain a high rate of deployment while both empowering engineers and managing security, we designed our new deployment system: Codeflow.
Our internal deployment system: Codeflow
From June to July of 2015, we started self-deploying Codeflow with Codeflow and migrated both GDAX and then Coinbase into our new deployment pipeline in AWS. At the same time, we started to onboard more of the engineering team onto Codeflow. In giving our engineers the confidence they needed to move fast, we worked to encourage more people to safely deploy more often. Some of the things we do that allow us to maintain high deployment velocity include:
Consensus : no single person (or point of failure) can make any changes to our production environment, but together with varying degrees of consensus, engineers are empowered to move fast.
: no single person (or point of failure) can make any changes to our production environment, but together with varying degrees of consensus, engineers are empowered to move fast. Safe Deploys : deploying to production is always safe. Anyone can redeploy any service at any time. We rely on service level health checks to make sure systems are acting normally before a blue/green deploy completes. Other heuristics like preventing the deploy of old or unsafe commits maximize the probability the deploys are always safe. If the deploy button is green, anyone can click it.
: deploying to production is always safe. Anyone can redeploy any service at any time. We rely on service level health checks to make sure systems are acting normally before a blue/green deploy completes. Other heuristics like preventing the deploy of old or unsafe commits maximize the probability the deploys are always safe. If the deploy button is green, anyone can click it. Onboarding : Deploying to production sounds scary to any self-aware new hire, so we encourage new engineers to deploy coinbase.com on their first day. We want everyone to know this is a safe thing to do.
: Deploying to production sounds scary to any self-aware new hire, so we encourage new engineers to deploy coinbase.com on their first day. We want everyone to know this is a safe thing to do. Security Pipeline : Several layers of inline security scanning provide the fastest possible feedback for known or likely security issues, before a commit is made deployable or a deploy completes.
: Several layers of inline security scanning provide the fastest possible feedback for known or likely security issues, before a commit is made deployable or a deploy completes. Failures: Deployment will always fail. When that happens, we’re quick to reinforce that it’s never the fault of the deployer. Instead, we look at how we can learn from our post-mortems and prevent that failure from occurring again with better automation.
With consensus, no single person can make any changes to our production environment, but together, engineers are empowered to move fast.
The impact Codeflow had on our deployment velocity was immediately obvious: despite increasing the security and controls of our pipeline into a more secure cloud, we increased our number of deployments 450% from 128 to 580 from June to July. This far out shadowed the ~30% increase in the size of our engineering team in those months and was a good indicator that our work was increasing the company’s velocity.
Deployment Velocity is up after migrating into Codeflow
As our complexity of services grew, so too did our rate of failure. Deploys can fail for a variety of reasons that can be both good and bad. Good failures might protect us from a breaking change or performance hit from going out into production but others stemming from bugs or poor configuration can hurt deployment velocity. Over the last year we’ve invested in reducing failures through improved automation. As we started to deploy all of our services through Codeflow in July we peaked at 27% of all deployments failing. As we’ve improved our deployment resilience and increased early feedback on possible issues to engineers, we’ve since brought our failure rate down to ~15% and are still improving.
Deployment failures initially increased after Heroku
As the team came to trust this new pipeline we began to further increase developer velocity through the introduction of new services. These services included better encapsulation of existing functionality and completely new products, both internal and external, as our anti-fraud, security, devops, product teams continued to scale. You can see the full growth of our services below, now up to 82 today. Included in these new services are brand new payment and wallet services that can now intentionally evolve with much more rigor than forward facing products.
The growth of services at Coinbase
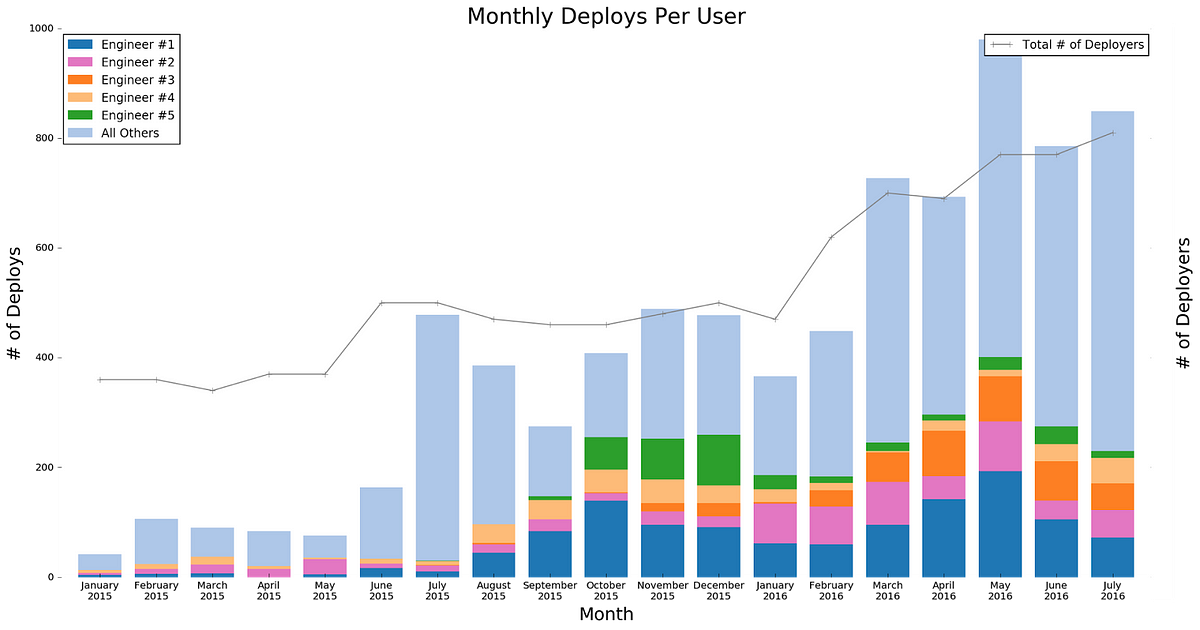
Since migrating into our new deployment pipeline we now have more people confidently deploying more services more frequently than ever. Before we ran our own Infrastructure our median monthly deployments per engineer was 8. After our migration to Codeflow that grew to 11 and we’re now up to a median of 16 deploys per developer per month. You can see a chart of that below, where you can see the deployment of our top-5 most frequently deploying engineers highlighted.
Increasing Developer Velocity Over Time
Now that we have the foundation to scale productively, we’re facing new challenges. Significant growth in usage is stress testing our systems and previously small-scale systems now need new optimizations to support our load. Looking ahead to the next quarter we’re working on improving our reliability, workflow and resilience of our infrastructure without compromising developer productivity.
Want to share more on developer productivity and velocity? We were inspired to write this by the annual State Of DevOps Report and would love to hear more about how your team is staying productive.
If you’re interested in empowering developers to move fast in a great environment, we’d love to work with you. We’re hiring for a variety of engineering roles here.
Thanks to Graham, Jack, Luke, Saso, Jeremy, and Brian for helping to make this possible!
Source: Coinbase.com
Powered by NewsAPI.org