Meta's new LLM-based test generator is a sneak peek to the future of development - 9 minutes read
Engineer’s Codex is a publication about real-world software engineering.
Meta recently released a paper called “Automated Unit Test Improvement using Large Language Models at Meta”. It’s a good look at how Big Tech is using AI internally to make development faster and software less buggy. For example, Google is using AI to speed up code reviews.
A major win of this paper is that while it integrates LLMs into a developer’s workflow, it also recommends fully-formed software improvements that are verified to be both correct and an improvement to current code coverage. Compare this to GitHub Copilot, where suggestions still have to be manually verified to work by the human - and we all know that debugging code is twice as hard as writing it.
Meta claims that this “this is the first paper to report on LLM-generated code that has been developed independent of human intervention (other than final review sign off), and landed into large scale industrial production systems with guaranteed assurances for improvement over the existing code base.”
Furthermore, there are solid principles that developers can take away in order to use AI effectively themselves.
Table of Contents (total read time: 7 minutes):
Key Points (1 minute read)Stats (1 minute read)Actionable Takeaways ← if you’re short on time, just read this! (3 minute read)How TestGen-LLM Works (2 minute read)SWE Quiz is for ambitious developers who want to make sure their software fundamentals are rock solid. Reveal gaps in your knowledge and make sure you really know what you’re doing both at work and while interviewing.
Take the tests for authentication, caching, databases, API Design, and more.
Check out SWE Quiz
TestGen-LLM uses an approach called ‘Assured LLM-based Software Engineering’ (Assured LLMSE), using private, internal LLMs that are probably fine-tuned with Meta’s codebase. This means that it uses LLMs to generate code improvements that are backed by verifiable guarantees of improvement and non-regression.
TestGen-LLM uses an ensemble approach to generate code improvements. This means that it uses multiple LLMs, prompts, and hyper-parameters to generate a set of candidate improvements, and then selects the best one. This approach can help to improve the quality of the generated improvements.
TestGen-LLM is specifically designed to improve existing human-written tests rather than generate code from scratch.
TestGen-LLM has been integrated into Meta's software engineering workflows. This means that it can be used to automatically improve tests as part of the development process. It would be cool to see some screenshots of how exactly it’s integrated, but the paper doesn’t provide any.
These stats are either direct quotes or paraphrased quotes from the paper.
The image above shows that: in an evaluation on Reels and Stories products for Instagram, 75% of TestGen-LLM test cases that were generated built correctly, 57% passed reliably, and 25% increased coverage.TestGen-LLM was able to improve 10% of all classes to which it was applied and 73% of its test improvements were accepted by developers, and landed into production.In a “test-a-thon” between engineers, where various Meta engineers created tests in order to increase Instagram’s test coverage, “the median number of lines of code added by a TestGen-LLM test was 2.5.”However, one test case “hit the jackpot” and covered 1,326 lines. This is a really important stat, which I iterate upon below.All improved cases generated during the “test-a-thon” did “cover at least one additional valid corner case, such as an early return and/or special processing for special values such as null and empty list.”TestGen-LLM is a good example of how LLMs can be used to improve dev productivity and software reliability in a time-efficient manner. There are a few takeaways I got from reading this paper that give us a look both to how Big Tech is implementing LLMs internally and to how any developer or engineering manager reading this can use LLMs in a more productive manner. (Note: many of these are my own personal opinions that I’ve taken away from the paper.)
Small context windows and scattered dependencies make LLMs nearly unusable for non-boilerplate solutions in large codebases. Aside from any privacy concerns, it’s not feasible to paste in multiple files of code into an LLM when there could be 20+ dependencies from across a codebase in a C++ header file (as an example). Even if you do paste in multiple files, there is a time and cognitive cost to actually using and trying the code outputted by an LLM in a chat window or even in the code editor by GitHub Copilot.
The price of extra cognitive load cannot be understated. Hacker News commenters find the inaccuracies of GPT-based tooling exhausting and unreliable. This is where the verification of outputs being both valid and non-regressive is extremely important.
This means that for a long-term productivity boost in large codebases, improvements will probably come in incremental, specialized use cases, like test generation and automatic suggestions during code reviews. These are also low risk ways to save cumulative developer time. Basically, “GPT wrappers” will continue to be useful 🙂.
The real value of LLMs here are displayed through the edge cases. The paradox of writing good code is that nobody ever gets credit for fixing problems that never happened.
Will Wilson writes:
“The fundamental problem of software testing… is that software has to handle many situations that the developer has never thought of or will never anticipate. This limits the value of testing, because if you had the foresight to write a test for a particular case, then you probably had the foresight to make the code handle that case too. This makes conventional testing great for catching regressions, but really terrible at catching all the “unknown unknowns” that life, the universe, and your endlessly creative users will throw at you.”Most of the test cases created by Meta’s TestGen-LLM only covered an extra 2.5 lines. However, one test case covered 1326 lines! The value of that one test case is exponentially more valuable than most of the previous test cases and exponentially improves the value of TestGen-LLM. LLMs can vigorously “think outside the box” and the value of catching unexpected edge cases is very high here.
In fact, it’s so high that the creator of FoundationDB’s startup, Antithesis, is entirely based on the fact that software testing edge cases are best found by AI. For reference, FoundationDB was acquired by Apple and is the basis for Apple iCloud’s billions of databases.
Base model LLMs aren’t “plug-n-play" and shouldn’t reasonably ever be expected to. Sure, they might output pristine React and Tailwind CSS code, but that’s a narrow use case in most production codebases. They need a fair amount of processing and filtering for code generation tasks that require correctness. Part of this processing means grounding LLMs with examples. Google and Meta both make suggestions based on existing code, where the results are much, much better than raw generation. LLMs used in production should take ideas from how Meta processes and filters LLM outputs, and most outputs should be expected to be discarded.
LLMs do work best integrated into workflows. This is a reason why GitHub Copilot is so popular and another reason why Google’s Workspace integrations are a great idea. Asking a chatbot works great for certain use cases, like debugging and boilerplate code generation, but chatbots can often fail at more complex use cases.
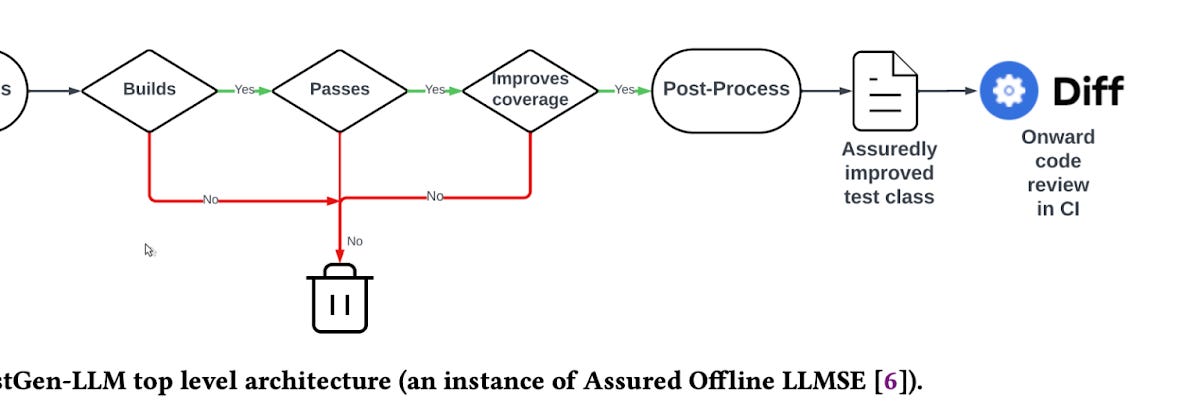
TestGen-LLM applies a series of semantic filters to candidate solutions generated by Meta’s internal LLMs, making sure that only the most valuable tests are preserved. Here’s how it works:
Filter 1: Buildability: Initially, TestGen-LLM checks if the generated code can be built within the app's existing infrastructure. Any code that fails to build is immediately discarded.
Filter 2: Execution (does the test pass?): Next, the system runs the tests that passed the buildability filter. Any test that doesn't pass is discarded. This step is crucial because, without a way to automatically determine the validity of a failing test (whether it's due to a bug or an incorrect assertion), TestGen-LLM opts to keep only those tests that can be used for regression testing (aka making sure they can protect current code against future regressions).
Filter 3: Flakiness: To address the issue of flakiness (tests that pass or fail inconsistently under the same conditions), TestGen-LLM employs repeated execution. A test must pass consistently across multiple (five) executions to be considered non-flaky.
Filter 3: Coverage Improvement: Finally, to ensure that new tests actually add value, TestGen-LLM evaluates them for their contribution to test coverage. Tests that do not enhance coverage by exploring new code paths or conditions are discarded. Only tests that provide new insights or protect against regressions are kept.
These processing filters are pretty important as they guarantee improvements to a test suite. It also shows that LLMs are very far from being “plug-and-play.”
The tests that successfully pass through all these filters are guaranteed to enhance the existing test suite, offering reliable regression testing capabilities without duplicating effort or wasting resources. Pre- and post-processing steps in TestGen-LLM facilitate the extraction and reconstruction of test classes, streamlining the integration of new tests into the software development workflow.
This paper is a good formalization of an use case that many devs probably already use LLMs like ChatGPT, Gemini, and Mistral/LLaMA for. Keeping it in writing is a good way of tracking the progress of future improvements on LLMs in the software reliability space. Unit tests are probably the lowest, most basic level of code generation where LLMs have the most immediate value, but as time goes on, we’ll definitely see LLMs be able to catch and test for bugs in increasingly complex software systems.
The question is - will that make software easier to develop in the long run or will it lead to a proliferation of software complexity in the future?
Source: Engineerscodex.com
Powered by NewsAPI.org